|
While state-of-the-art 3D Convolutional Neural Networks (CNN) achieve very good results on action recognition datasets, they are computationally very expensive and
require many GFLOPs. While the GFLOPs of a 3D CNN
can be decreased by reducing the temporal feature resolution within the network, there is no setting that is optimal for all input clips. In this work, we therefore introduce
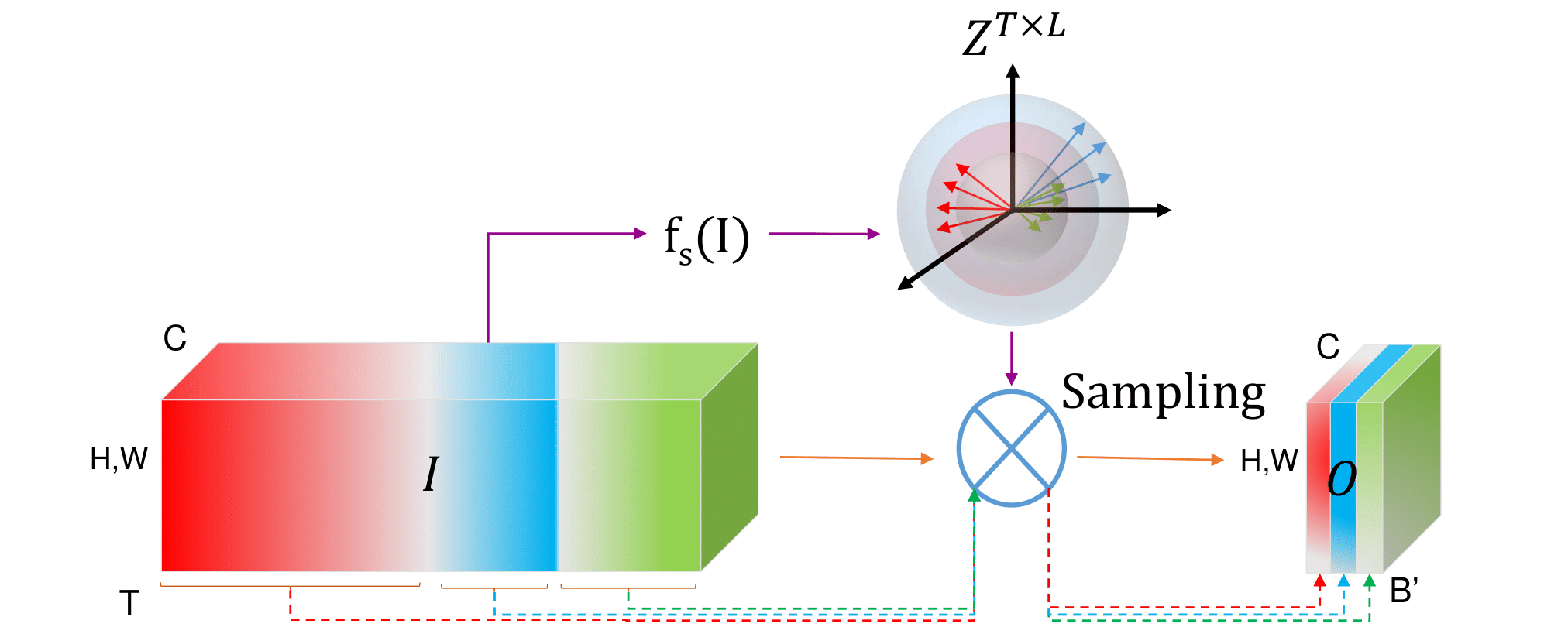
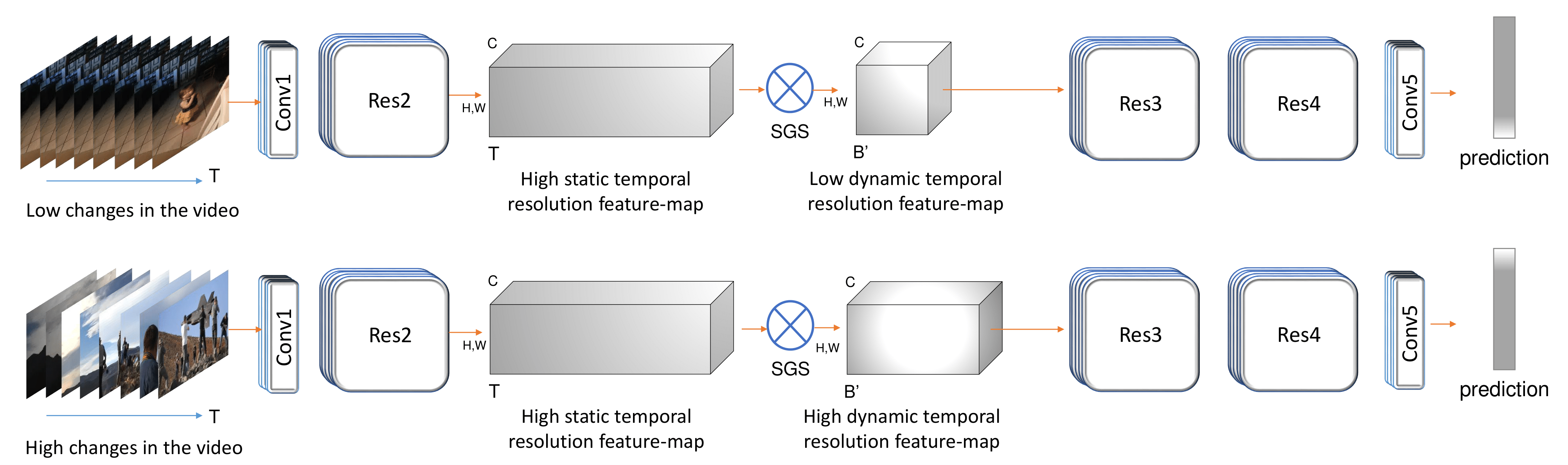
a differentiable Similarity Guided Sampling (SGS) module,
which can be plugged into any existing 3D CNN architecture. SGS empowers 3D CNNs by learning the similarity
of temporal features and grouping similar features together.
As a result, the temporal feature resolution is not anymore
static but it varies for each input video clip. By integrating SGS as an additional layer within current 3D CNNs, we
can convert them into much more efficient 3D CNNs with
adaptive temporal feature resolutions (ATFR) . Our evaluations show that the proposed module improves the stateof-the-art by reducing the computational cost (GFLOPs)
by half while preserving or even improving the accuracy.
We evaluate our module by adding it to multiple state-ofthe-art 3D CNNs on various datasets such as Kinetics600, Kinetics-400, mini-Kinetics, Something-Something V2,
UCF101, and HMDB51.
|